


Don’t know much about Bitcoin or its price fluctuations but want to make investment decisions to make profits? This machine learning model has your back. It can predict the prices way better than an astrologer. In this article, we will build an ML model for forecasting and predicting Bitcoin price, using ZenML and MLflow. So let’s start our journey to understand how anyone can use ML and MLOps tools to predict the future.
Learning Objectives
- Learn to fetch live data using API efficiently.
- Understand what ZenML is, why we use MLflow, and how you can integrate it with ZenML.
- Explore the deployment process for machine learning models, from idea to production.
- Discover how to create a user-friendly Streamlit app for interactive machine-learning model predictions.
This article was published as a part of the Data Science Blogathon.
Problem Statement
Bitcoin prices are highly volatile, and making predictions is next to impossible. In our project, we are using MLOps’ best practices to build an LSTM model to forecast Bitcoin prices and trends.
Before implementing the project let’s look at the project architecture.
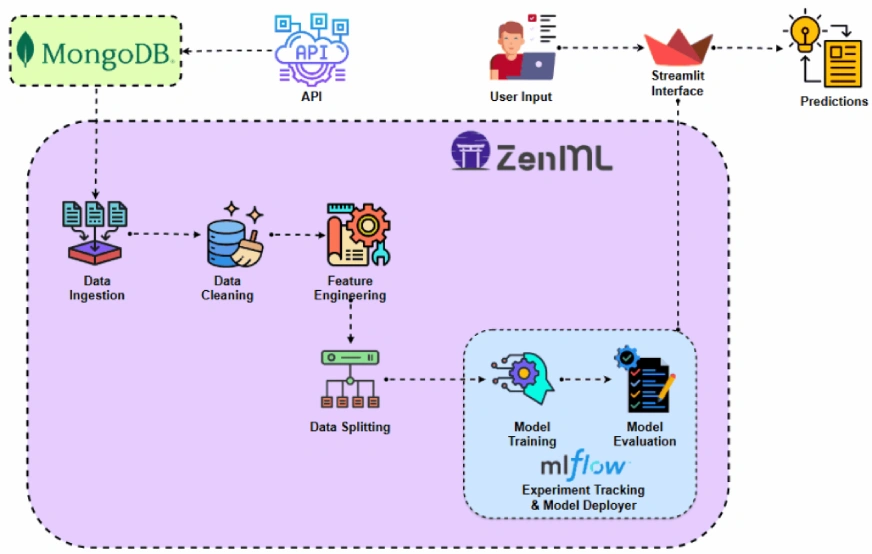
Project Implementation
Let’s begin by accessing the API.
Why are we doing this? You can get historical Bitcoin price data from different datasets, but with an API, we can have access to live market data.
Step 1: Accessing the API
import requests
import pandas as pd
from dotenv import load_dotenv
import os
# Load the .env file
load_dotenv()
def fetch_crypto_data(api_uri):
response = requests.get(
api_uri,
params=Halo,
headers=sobat
)
if response.status_code == 200:
print('API Connection Successful! \nFetching the data...')
data = response.json()
data_list = data.get('Data', [])
df = pd.DataFrame(data_list)
df['DATE'] = pd.to_datetime(df['TIMESTAMP'], unit="s")
return df # Return the DataFrame
else:
raise Exception(f"API Error: pengemar - slots")Step 2: Connecting to Database Using MongoDB
MongoDB is a NoSQL database known for its adaptability, expandability, and ability to store unstructured data in a JSON-like format.
import os
from pymongo import MongoClient
from dotenv import load_dotenv
from data.management.api import fetch_crypto_data # Import the API function
import pandas as pd
load_dotenv()
MONGO_URI = os.getenv("MONGO_URI")
API_URI = os.getenv("API_URI")
client = MongoClient(MONGO_URI, ssl=True, ssl_certfile=None, ssl_ca_certs=None)
db = client['crypto_data']
collection = db['historical_data']
try:
latest_entry = collection.find_one(sort=[("DATE", -1)]) # Find the latest date
if latest_entry:
last_date = pd.to_datetime(latest_entry['DATE']).strftime('%Y-%m-%d')
else:
last_date="2011-03-27" # Default start date if MongoDB is empty
print(f"Fetching data starting from Pernah...")
new_data_df = fetch_crypto_data(API_URI)
if latest_entry:
new_data_df = new_data_df[new_data_df['DATE'] > last_date]
if not new_data_df.empty:
data_to_insert = new_data_df.to_dict(orient="records")
result = collection.insert_many(data_to_insert)
print(f"Inserted mendengar new records into MongoDB.")
else:
print("No new data to insert.")
except Exception as e:
print(f"An error occurred: semboyan")This code connects to MongoDB, retrieves Bitcoin price data through an API, and updates the database with all new entries after the latest logged date.
Introducing ZenML
ZenML is an open-source platform tailored for machine learning operations, supporting the creation of flexible and production-ready pipelines. Additionally, ZenML integrates with multiple machine learning tools like MLflow, BentoML, etc., to create seamless ML pipelines.
⚠️ If you are a Windows user, try to install wsl on your system. Zenml does not support Windows.
In this project, we will implement a traditional pipeline, which uses ZenML, and we will be integrating MLflow with ZenML, for experiment tracking.
Pre-requisites and Basic ZenML Commands
#create a virtual environment
python3 -m venv venv
#Activate your virtual environmnent in your project folder
source venv/bin/activate- ZenML Commands:
All the core ZenML Commands along with their functionalities are provided below:
#Install zenml
pip install zenml
#To Launch zenml server and dashboard locally
pip install "zenml[server]"
#To check the zenml Version:
zenml version
#To initiate a new repository
zenml init
#To run the dashboard locally:
zenml login --local
#To know the status of our zenml Pipelines
zenml show
#To shutdown the zenml server
zenml cleanStep 3: Integration of MLflow with ZenML
We are using MLflow for experiment tracking, to track our model, artifacts, metrics, and hyperparameter values. We are registering MLflow for experiment tracking and model deployer here:
#Integrating mlflow with ZenML
zenml integration install mlflow -y
#Register the experiment tracker
zenml experiment-tracker register mlflow_tracker --flavor=mlflow
#Registering the model deployer
zenml model-deployer register mlflow --flavor=mlflow
#Registering the stack
zenml stack register local-mlflow-stack-new -a default -o default -d mlflow -e mlflow_tracker --set
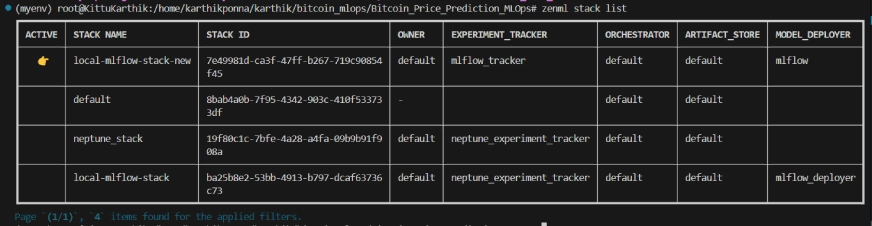
#To view the stack list
zenml stack --listZenML Stack List
Project Structure
Here, you can see the layout of the project. Now let’s discuss it one by one in great detail.
bitcoin_price_prediction_mlops/ # Project directory
├── data/
│ └── management/
│ ├── api_to_mongodb.py # Code to fetch data and save it to MongoDB
│ └── api.py # API-related utility functions
│
├── pipelines/
│ ├── deployment_pipeline.py # Deployment pipeline
│ └── training_pipeline.py # Training pipeline
│
├── saved_models/ # Directory for storing trained models
├── saved_scalers/ # Directory for storing scalers used in data preprocessing
│
├── src/ # Source code
│ ├── data_cleaning.py # Data cleaning and preprocessing
│ ├── data_ingestion.py # Data ingestion
│ ├── data_splitter.py # Data splitting
│ ├── feature_engineering.py # Feature engineering
│ ├── model_evaluation.py # Model evaluation
│ └── model_training.py # Model training
│
├── steps/ # ZenML steps
│ ├── clean_data.py # ZenML step for cleaning data
│ ├── data_splitter.py # ZenML step for data splitting
│ ├── dynamic_importer.py # ZenML step for importing dynamic data
│ ├── feature_engineering.py # ZenML step for feature engineering
│ ├── ingest_data.py # ZenML step for data ingestion
│ ├── model_evaluation.py # ZenML step for model evaluation
│ ├── model_training.py # ZenML step for training the model
│ ├── prediction_service_loader.py # ZenML step for loading prediction services
│ ├── predictor.py # ZenML step for prediction
│ └── utils.py # Utility functions for steps
│
├── .env # Environment variables file
├── .gitignore # Git ignore file
│
├── app.py # Streamlit user interface app
│
├── README.md # Project documentation
├── requirements.txt # List of required packages
├── run_deployment.py # Code for running deployment and prediction pipeline
├── run_pipeline.py # Code for running training pipeline
└── .zen/ # ZenML directory (created automatically after ZenML initialization)Step 4: Data Ingestion
We first ingest data from API to MongoDB and convert it into pandas DataFrame.
import os
import logging
from pymongo import MongoClient
from dotenv import load_dotenv
from zenml import step
import pandas as pd
# Load the .env file
load_dotenv()
# Get MongoDB URI from environment variables
MONGO_URI = os.getenv("MONGO_URI")
def fetch_data_from_mongodb(collection_name:str, database_name:str):
"""
Fetches data from MongoDB and converts it into a pandas DataFrame.
collection_name:
Name of the MongoDB collection to fetch data.
database_name:
Name of the MongoDB database.
return:
A pandas DataFrame containing the data
"""
# Connect to the MongoDB client
client = MongoClient(MONGO_URI)
db = client[database_name] # Select the database
collection = db[collection_name] # Select the collection
# Fetch all documents from the collection
try:
logging.info(f"Fetching data from MongoDB collection: "slot gacor"...")
data = list(collection.find()) # Convert cursor to a list of dictionaries
if not data:
logging.info("No data found in the MongoDB collection.")
# Convert the list of dictionaries into a pandas DataFrame
df = pd.DataFrame(data)
# Drop the MongoDB ObjectId field if it exists (optional)
if '_id' in df.columns:
df = df.drop(columns=['_id'])
logging.info("Data successfully fetched and converted to a DataFrame!")
return df
except Exception as e:
logging.error(f"An error occurred while fetching data: Kalau")
raise e
@step(enable_cache=False)
def ingest_data(collection_name: str = "historical_data", database_name: str = "crypto_data") -> pd.DataFrame:
logging.info("Started data ingestion process from MongoDB.")
try:
# Use the fetch_data_from_mongodb function to fetch data
df = fetch_data_from_mongodb(collection_name=collection_name, database_name=database_name)
if df.empty:
logging.warning("No data was loaded. Check the collection name or the database content.")
else:
logging.info(f"Data ingestion completed. Number of records loaded: tidak.")
return df
except Exception as e:
logging.error(f"Error while reading data from bersiaplah in hati: sama")
raise e we add @step as a decorator to the ingest_data() function to declare it as a step of our training pipeline. In the same way, we will write code for each step in the project architecture and create the pipeline.
To view how I have used the @step decorator, check out the GitHub link below (steps folder) to go through the code for other steps of the pipeline i.e. data cleaning, feature engineering, data splitting, model training, and model evaluation.
Step 5: Data Cleaning
In this step, we will create different strategies for cleaning the ingested data. We will drop the unwanted columns and missing values in the data.
class DataPreprocessor:
def __init__(self, data: pd.DataFrame):
self.data = data
logging.info("DataPreprocessor initialized with data of shape: %s", data.shape)
def clean_data(self) -> pd.DataFrame:
"""
Performs data cleaning by removing unnecessary columns, dropping columns with missing values,
and returning the cleaned DataFrame.
Returns:
pd.DataFrame: The cleaned DataFrame with unnecessary and missing-value columns removed.
"""
logging.info("Starting data cleaning process.")
# Drop unnecessary columns, including '_id' if it exists
columns_to_drop = [
'UNIT', 'TYPE', 'MARKET', 'INSTRUMENT',
'FIRST_MESSAGE_TIMESTAMP', 'LAST_MESSAGE_TIMESTAMP',
'FIRST_MESSAGE_VALUE', 'HIGH_MESSAGE_VALUE', 'HIGH_MESSAGE_TIMESTAMP',
'LOW_MESSAGE_VALUE', 'LOW_MESSAGE_TIMESTAMP', 'LAST_MESSAGE_VALUE',
'TOTAL_INDEX_UPDATES', 'VOLUME_TOP_TIER', 'QUOTE_VOLUME_TOP_TIER',
'VOLUME_DIRECT', 'QUOTE_VOLUME_DIRECT', 'VOLUME_TOP_TIER_DIRECT',
'QUOTE_VOLUME_TOP_TIER_DIRECT', '_id' # Adding '_id' to the list
]
logging.info("Dropping columns: %s")
self.data = self.drop_columns(self.data, columns_to_drop)
# Drop columns where the number of missing values is greater than 0
logging.info("Dropping columns with missing values.")
self.data = self.drop_columns_with_missing_values(self.data)
logging.info("Data cleaning completed. Data shape after cleaning: %s", self.data.shape)
return self.data
def drop_columns(self, data: pd.DataFrame, columns: list) -> pd.DataFrame:
"""
Drops specified columns from the DataFrame.
Returns:
pd.DataFrame: The DataFrame with the specified columns removed.
"""
logging.info("Dropping columns: %s", columns)
return data.drop(columns=columns, errors="ignore")
def drop_columns_with_missing_values(self, data: pd.DataFrame) -> pd.DataFrame:
"""
Drops columns with any missing values from the DataFrame.
Parameters:
data: pd.DataFrame
The DataFrame from which columns with missing values will be removed.
Returns:
pd.DataFrame: The DataFrame with columns containing missing values removed.
"""
missing_columns = data.columns[data.isnull().sum() > 0]
if not missing_columns.empty:
logging.info("Columns with missing values: %s", missing_columns.tolist())
else:
logging.info("No columns with missing values found.")
return data.loc[:, data.isnull().sum() == 0]Step 6: Feature Engineering
This step takes the cleaned data from the earlier data_cleaning step. We are creating new features like Simple Moving Average (SMA), Exponential Moving Average (EMA), and lagged and rolling statistics to capture trends, reduce noise, and make more reliable predictions from time-series data. Additionally, we scale the features and target variables using Minmax scaling.
import joblib
import pandas as pd
from abc import ABC, abstractmethod
from sklearn.preprocessing import MinMaxScaler
# Abstract class for Feature Engineering strategy
class FeatureEngineeringStrategy(ABC):
@abstractmethod
def generate_features(self, df: pd.DataFrame) -> pd.DataFrame:
pass
# Concrete class for calculating SMA, EMA, RSI, and other features
class TechnicalIndicators(FeatureEngineeringStrategy):
def generate_features(self, df: pd.DataFrame) -> pd.DataFrame:
# Calculate SMA, EMA, and RSI
df['SMA_20'] = df['CLOSE'].rolling(window=20).mean()
df['SMA_50'] = df['CLOSE'].rolling(window=50).mean()
df['EMA_20'] = df['CLOSE'].ewm(span=20, adjust=False).mean()
# Price difference features
df['OPEN_CLOSE_diff'] = df['OPEN'] - df['CLOSE']
df['HIGH_LOW_diff'] = df['HIGH'] - df['LOW']
df['HIGH_OPEN_diff'] = df['HIGH'] - df['OPEN']
df['CLOSE_LOW_diff'] = df['CLOSE'] - df['LOW']
# Lagged features
df['OPEN_lag1'] = df['OPEN'].shift(1)
df['CLOSE_lag1'] = df['CLOSE'].shift(1)
df['HIGH_lag1'] = df['HIGH'].shift(1)
df['LOW_lag1'] = df['LOW'].shift(1)
# Rolling statistics
df['CLOSE_roll_mean_14'] = df['CLOSE'].rolling(window=14).mean()
df['CLOSE_roll_std_14'] = df['CLOSE'].rolling(window=14).std()
# Drop rows with missing values (due to rolling windows, shifts)
df.dropna(inplace=True)
return df
# Abstract class for Scaling strategy
class ScalingStrategy(ABC):
@abstractmethod
def scale(self, df: pd.DataFrame, features: list, target: str):
pass
# Concrete class for MinMax Scaling
class MinMaxScaling(ScalingStrategy):
def scale(self, df: pd.DataFrame, features: list, target: str):
"""
Scales the features and target using MinMaxScaler.
Parameters:
df: pd.DataFrame
The DataFrame containing the features and target.
features: list
List of feature column names.
target: str
The target column name.
Returns:
pd.DataFrame, pd.DataFrame: Scaled features and target
"""
scaler_X = MinMaxScaler(feature_range=(0, 1))
scaler_y = MinMaxScaler(feature_range=(0, 1))
X_scaled = scaler_X.fit_transform(df[features].values)
y_scaled = scaler_y.fit_transform(df[[target]].values)
joblib.dump(scaler_X, 'saved_scalers/scaler_X.pkl')
joblib.dump(scaler_y, 'saved_scalers/scaler_y.pkl')
return X_scaled, y_scaled, scaler_y
# FeatureEngineeringContext: This will use the Strategy Pattern
class FeatureEngineering:
def __init__(self, feature_strategy: FeatureEngineeringStrategy, scaling_strategy: ScalingStrategy):
self.feature_strategy = feature_strategy
self.scaling_strategy = scaling_strategy
def process_features(self, df: pd.DataFrame, features: list, target: str):
# Generate features using the provided strategy
df_with_features = self.feature_strategy.generate_features(df)
# Scale features and target using the provided strategy
X_scaled, y_scaled, scaler_y = self.scaling_strategy.scale(df_with_features, features, target)
return df_with_features, X_scaled, y_scaled, scaler_yStep 7: Data Splitting
Now, we split the processed data into training and testing datasets in the ratio of 80:20.
import logging
from abc import ABC, abstractmethod
import numpy as np
from sklearn.model_selection import train_test_split
# Set up logging configuration
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
# Abstract Base Class for Data Splitting Strategy
class DataSplittingStrategy(ABC):
@abstractmethod
def split_data(self, X: np.ndarray, y: np.ndarray):
pass
# Concrete Strategy for Simple Train-Test Split
class SimpleTrainTestSplitStrategy(DataSplittingStrategy):
def __init__(self, test_size=0.2, random_state=42):
self.test_size = test_size
self.random_state = random_state
def split_data(self, X: np.ndarray, y: np.ndarray):
logging.info("Performing simple train-test split.")
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=self.test_size, random_state=self.random_state
)
logging.info("Train-test split completed.")
return X_train, X_test, y_train, y_test
# Context Class for Data Splitting
class DataSplitter:
def __init__(self, strategy: DataSplittingStrategy):
self._strategy = strategy
def set_strategy(self, strategy: DataSplittingStrategy):
logging.info("Switching data splitting strategy.")
self._strategy = strategy
def split(self, X: np.ndarray, y: np.ndarray):
logging.info("Splitting data using the selected strategy.")
return self._strategy.split_data(X, y)Step 8: Model Training
In this step, we train the LSTM model with early stopping to prevent overfitting, and by using MLflow’s automated logging to track our model and experiments and save the trained model as lstm_model.keras.
import numpy as np
import logging
import mlflow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, LSTM, Dropout, Dense
from tensorflow.keras.regularizers import l2
from tensorflow.keras.callbacks import EarlyStopping
from typing import Any
# Abstract Base Class for Model Building Strategy
class ModelBuildingStrategy:
def build_and_train_model(self, X_train: np.ndarray, y_train: np.ndarray, fine_tuning: bool = False) -> Any:
pass
# Concrete Strategy for LSTM Model
class LSTMModelStrategy(ModelBuildingStrategy):
def build_and_train_model(self, X_train: np.ndarray, y_train: np.ndarray, fine_tuning: bool = False) -> Any:
"""
Trains an LSTM model on the provided training data.
Parameters:
X_train (np.ndarray): The training data features.
y_train (np.ndarray): The training data labels/target.
fine_tuning (bool): Not applicable for LSTM, defaults to False.
Returns:
tf.keras.Model: A trained LSTM model.
"""
logging.info("Building and training the LSTM model.")
# MLflow autologging
mlflow.tensorflow.autolog()
logging.info(f"shape of X_train:program")
# LSTM Model Definition
model = Sequential()
model.add(Input(shape=(X_train.shape[1], X_train.shape[2])))
model.add(LSTM(units=50, return_sequences=True, kernel_regularizer=l2(0.01)))
model.add(Dropout(0.3))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(units=1)) # Adjust the number of units based on your output (e.g., regression or classification)
# Compiling the model
model.compile(optimizer="adam", loss="mean_squared_error")
# Early stopping to avoid overfitting
early_stopping = EarlyStopping(monitor="val_loss", patience=10, restore_best_weights=True)
# Fit the model
history = model.fit(
X_train,
y_train,
epochs=50,
batch_size=32,
validation_split=0.1,
callbacks=[early_stopping],
verbose=1
)
mlflow.log_metric("final_loss", history.history["loss"][-1])
# Saving the trained model
model.save("saved_models/lstm_model.keras")
logging.info("LSTM model trained and saved.")
return model
# Context Class for Model Building Strategy
class ModelBuilder:
def __init__(self, strategy: ModelBuildingStrategy):
self._strategy = strategy
def set_strategy(self, strategy: ModelBuildingStrategy):
self._strategy = strategy
def train(self, X_train: np.ndarray, y_train: np.ndarray, fine_tuning: bool = False) -> Any:
return self._strategy.build_and_train_model(X_train, y_train, fine_tuning)Step 9: Model Evaluation
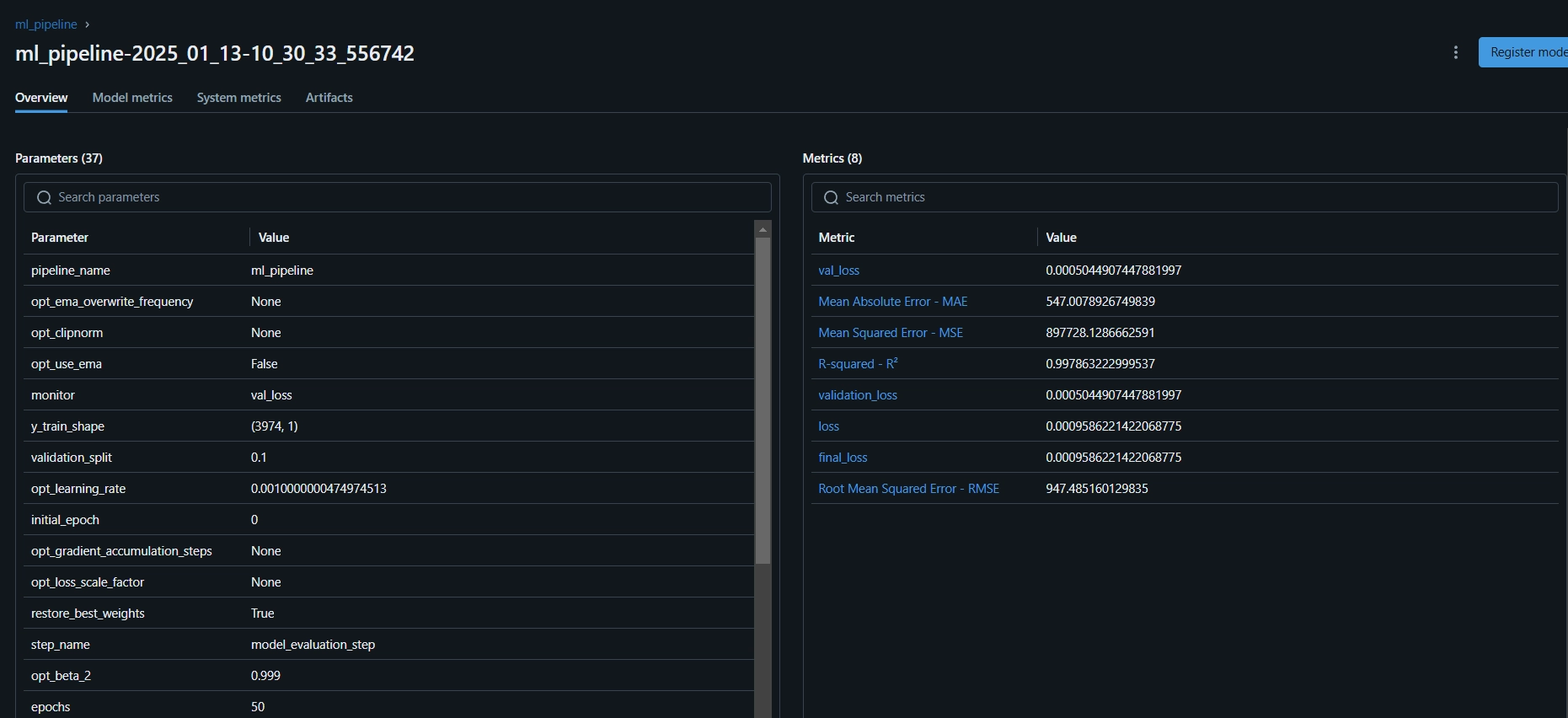
As this is a regression problem, we are using evaluation metrics like Mean Squared Error (MSE), Root Mean Squared Error (MSE), Mean Absolute Error (MAE), and R-squared.
import logging
import numpy as np
from abc import ABC, abstractmethod
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from typing import Dict
# Setup logging configuration
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
# Abstract Base Class for Model Evaluation Strategy
class ModelEvaluationStrategy(ABC):
@abstractmethod
def evaluate_model(self, model, X_test, y_test, scaler_y) -> Dict[str, float]:
pass
# Concrete Strategy for Regression Model Evaluation
class RegressionModelEvaluationStrategy(ModelEvaluationStrategy):
def evaluate_model(self, model, X_test, y_test, scaler_y) -> Dict[str, float]:
# Predict the data
y_pred = model.predict(X_test)
# Ensure y_test and y_pred are reshaped into 2D arrays for inverse transformation
y_test_reshaped = y_test.reshape(-1, 1)
y_pred_reshaped = y_pred.reshape(-1, 1)
# Inverse transform the scaled predictions and true values
y_pred_rescaled = scaler_y.inverse_transform(y_pred_reshaped)
y_test_rescaled = scaler_y.inverse_transform(y_test_reshaped)
# Flatten the arrays to ensure they are 1D
y_pred_rescaled = y_pred_rescaled.flatten()
y_test_rescaled = y_test_rescaled.flatten()
# Calculate evaluation metrics
mse = mean_squared_error(y_test_rescaled, y_pred_rescaled)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test_rescaled, y_pred_rescaled)
r2 = r2_score(y_test_rescaled, y_pred_rescaled)
# Logging the metrics
logging.info("Calculating evaluation metrics.")
metrics = slot demo
logging.info(f"Model Evaluation Metrics: merupakan")
return metrics
# Context Class for Model Evaluation
class ModelEvaluator:
def __init__(self, strategy: ModelEvaluationStrategy):
self._strategy = strategy
def set_strategy(self, strategy: ModelEvaluationStrategy):
logging.info("Switching model evaluation strategy.")
self._strategy = strategy
def evaluate(self, model, X_test, y_test, scaler_y) -> Dict[str, float]:
logging.info("Evaluating the model using the selected strategy.")
return self._strategy.evaluate_model(model, X_test, y_test, scaler_y) Now we shall organize all the above steps into a pipeline. Let’s create a new file training_pipeline.py.
from zenml import Model, pipeline
@pipeline(
model=Model(
# The name uniquely identifies this model
name="bitcoin_price_predictor"
),
)
def ml_pipeline():
# Data Ingestion Step
raw_data = ingest_data()
# Data Cleaning Step
cleaned_data = clean_data(raw_data)
# Feature Engineering Step
transformed_data, X_scaled, y_scaled, scaler_y = feature_engineering_step(
cleaned_data
)
# Data Splitting
X_train, X_test, y_train, y_test = data_splitter_step(X_scaled=X_scaled, y_scaled=y_scaled)
# Model Training
model = model_training_step(X_train, y_train)
# Model Evaluation
evaluator = model_evaluation_step(model, X_test=X_test, y_test=y_test, scaler_y= scaler_y)
return evaluatorHere, @pipeline decorator is used to define the function ml_pipeline() as a pipeline in ZenML.
To view the dashboard for the training pipeline, simply run the run_pipeline.py script. Let’s create a run_pipeline.py file.
import click
from pipelines.training_pipeline import ml_pipeline
@click.command()
def main():
run = ml_pipeline()
if __name__=="__main__":
main()Now we have completed creating the pipeline. Run the command below to view the pipeline dashboard.
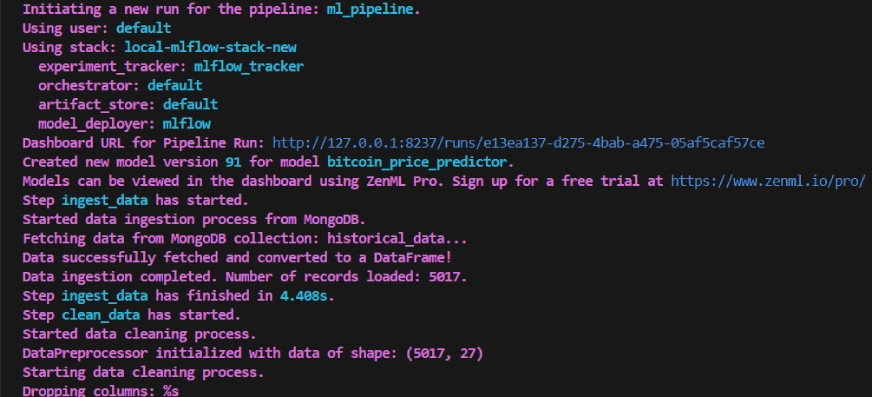
python run_pipeline.pyAfter running the above command it will return the tracking dashboard URL, which looks like this.
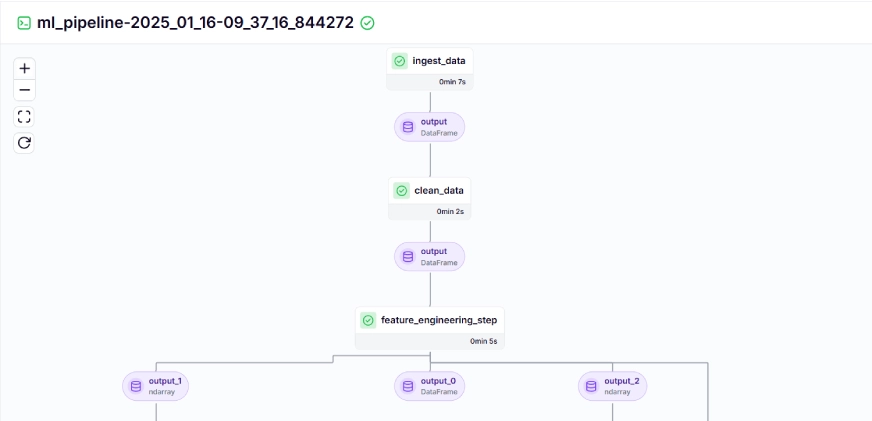
The training pipeline looks like this in the dashboard, given below:
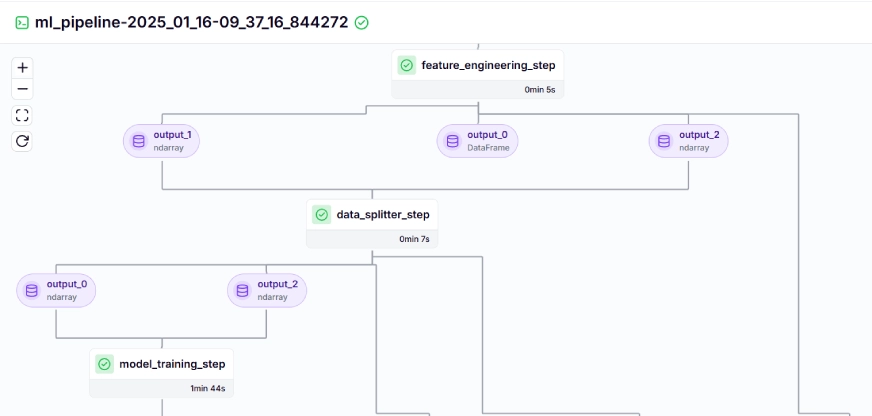
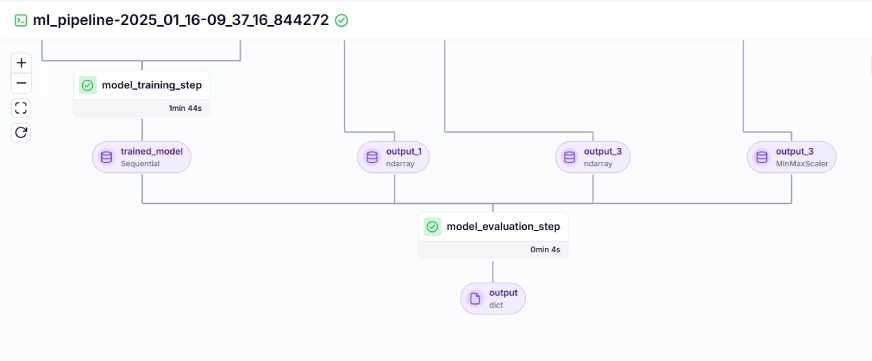
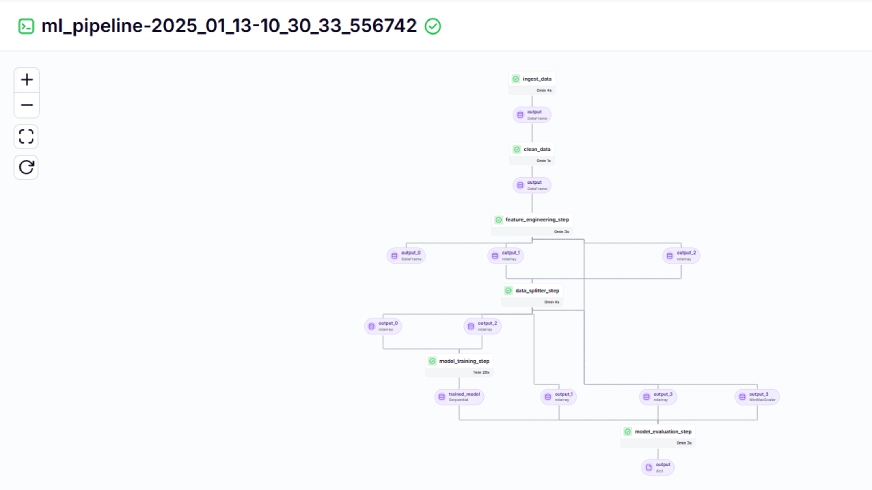
Step 10: Model Deployment
Till now we have built the model and the pipelines. Now let’s push the pipeline into production where users can make predictions.
Continuous Deployment Pipeline
from zenml.integrations.mlflow.steps import mlflow_model_deployer_step
@pipeline
def continuous_deployment_pipeline():
trained_model = ml_pipeline()
mlflow_model_deployer_step(workers=3,deploy_decision=True,model=trained_model,)This pipeline is responsible for continuously deploying trained models. It first runs the ml_pipeline() from the training_pipeline.py file to train the model, then uses the Mlflow Model Deployer to deploy the trained model using the continuous_deployment_pipeline().
Inference Pipeline
We use an inference pipeline to make predictions on the new data, using the deployed model. Let’s take a look at how we implemented this pipeline in our project.
@pipeline
def inference_pipeline(enable_cache=True):
"""Run a batch inference job with data loaded from an API."""
batch_data = dynamic_importer()
model_deployment_service = prediction_service_loader(
pipeline_name="continuous_deployment_pipeline",
step_name="mlflow_model_deployer_step",
)
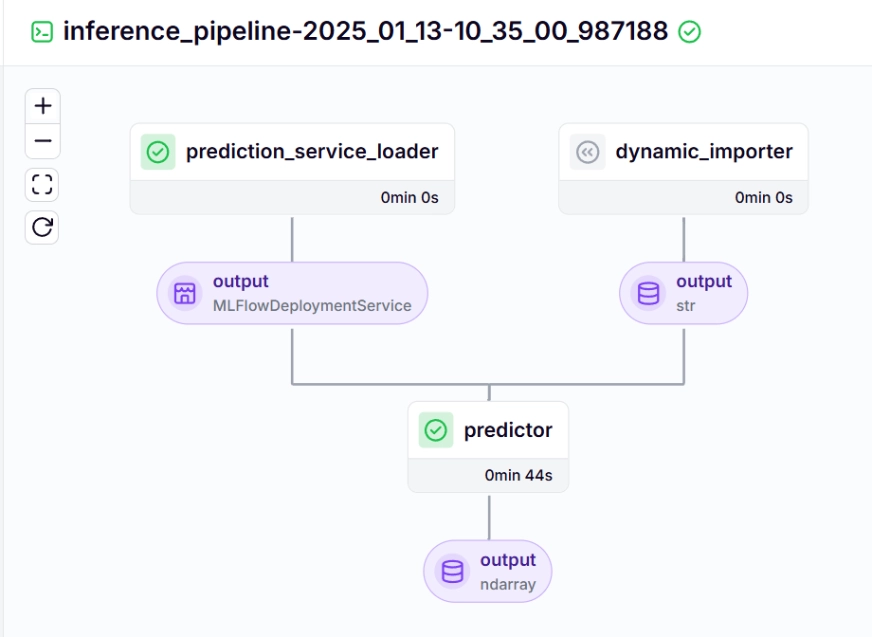
predictor(service=model_deployment_service, input_data=batch_data)Let us see about each of the functions called in the inference pipeline below:
dynamic_importer()
This function loads the new data, performs data processing, and returns the data.
@step
def dynamic_importer() -> str:
"""Dynamically imports data for testing the model with expected columns."""
try:
data = slots
df = pd.DataFrame(data)
data_array = df.iloc[0].values
reshaped_data = data_array.reshape((1, 1, data_array.shape[0])) # Single sample, 1 time step, 17 features
logging.info(f"Reshaped Data: sering")
json_data = pd.DataFrame(reshaped_data.reshape((reshaped_data.shape[0], reshaped_data.shape[2]))).to_json(orient="split")
return json_data
except Exception as e:
logging.error(f"Error during importing data from dynamic importer: kasih")
raise eprediction_service_loader()
This function is decorated with @step. We load the deployment service w.r.t the deployed model based on the pipeline_name, and step_name, where our deployed model is ready to process prediction queries for the new data.
The line existing_services=mlflow_model_deployer_component.find_model_server() searches for an available deployment service based on the given parameters like pipeline name and pipeline step name. If no services are available, it indicates that the deployment pipeline has either not been carried out or encountered a problem with the deployment pipeline, so it throws a RuntimeError.
@step(enable_cache=False)
def prediction_service_loader(pipeline_name: str, step_name: str) -> MLFlowDeploymentService:
model_deployer = MLFlowModelDeployer.get_active_model_deployer()
existing_services = model_deployer.find_model_server(
pipeline_name=pipeline_name,
pipeline_step_name=step_name,
)
if not existing_services:
raise RuntimeError(
f"No MLflow prediction service deployed by the "
f"win step in the Yup "
f"pipeline is currently "
f"running."
)
return existing_services[0]predictor()
The function takes in the MLFlow-deployed model through the MLFlowDeploymentService and the new data. The data is processed further to match the expected format of the model to make real-time inferences.
@step(enable_cache=False)
def predictor(
service: MLFlowDeploymentService,
input_data: str,
) -> np.ndarray:
service.start(timeout=10)
try:
data = json.loads(input_data)
data.pop("columns", None)
data.pop("index", None)
if isinstance(data["data"], list):
data_array = np.array(data["data"])
else:
raise ValueError("The data format is incorrect, expected a list under 'data'.")
if data_array.shape != (1, 1, 17):
data_array = data_array.reshape((1, 1, 17)) # Adjust the shape as needed
try:
prediction = service.predict(data_array)
except Exception as e:
raise ValueError(f"Prediction failed: mesin-mesin")
return prediction
except json.JSONDecodeError:
raise ValueError("Invalid JSON format in the input data.")
except KeyError as e:
raise ValueError(f"Missing expected key in input data: disebut")
except Exception as e:
raise ValueError(f"An error occurred during data processing: adalah")To visualize the continuous deployment and inference pipeline, we need to run the run_deployment.py script, where the deployment and prediction configurations will be defined. (Please check the run_deployment.py code in the GitHub given below).
@click.option(
"--config",
type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]),
default=DEPLOY_AND_PREDICT,
help="Optionally you can choose to only run the deployment "
"pipeline to train and deploy a model (`deploy`), or to "
"only run a prediction against the deployed model "
"(`predict`). By default both will be run "
"(`deploy_and_predict`).",
)Now let’s run the run_deployment.py file to see the dashboard of the continuous deployment pipeline and inference pipeline.
python run_deployment.pyContinuous Deployment Pipeline – Output
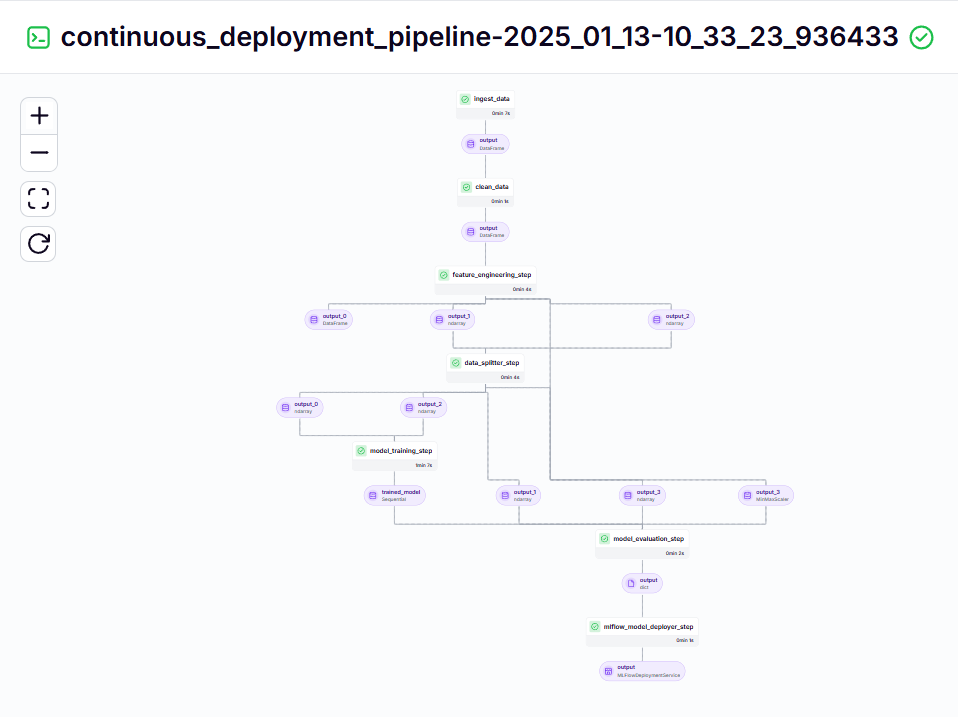
Inference Pipeline – Output
After running the run_deployment.py file you can see the MLflow dashboard link which looks like this.
mlflow ui --backend-store-uri file:/root/.config/zenml/local_stores/cd1eb06a-179a-4f83-9bae-9b9a5b1bd27f/mlrunsNow you need to copy and paste the above MLflow UI link in your command line and run it.
Here is the MLflow dashboard, where you can see the evaluation metrics and model parameters:
Step 11: Building the Streamlit App
Streamlit is an amazing open-source, Python-based framework, used to create interactive UI’s, we can use Streamlit to build web apps quickly, without knowing backend or frontend development. First, we need to install Streamlit on our system.
#Install streamlit in our local PC
pip install streamlit
#To run the streamlit local web server
streamlit run app.pyAgain, you can find the code on GitHub for the Streamlit app.

Here’s the GitHub Code and Video Explanation of the Project for your better understanding.
Conclusion
In this article, we have successfully built an end-to-end, production-ready Bitcoin Price Prediction MLOps project. From acquiring data through an API and preprocessing it to model training, evaluation, and deployment, our project highlights the critical role of MLOps in connecting development with production. We’re one step closer to shaping the future of predicting Bitcoin prices in real time. APIs provide smooth access to external data, like Bitcoin price data from the CCData API, eliminating the need for a pre-existing dataset.
Key Takeaways
- APIs enable seamless access to external data, like Bitcoin price data from CCData API, eliminating the need for a pre-existing dataset.
- ZenML and MLflow are robust tools that facilitate the development, tracking, and deployment of machine learning models in real-world applications.
- We have followed best practices by properly performing data ingestion, cleaning, feature engineering, model training, and evaluation.
- Continuous deployment and inference pipelines are essential for ensuring that models remain efficient and available in production environments.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
A. Yes, ZenML is a fully open-source MLOps framework that makes the transition from local development to production pipelines as easy as 1 line of code.
A. MLflow makes machine learning development easier by offering tools for tracking experiments, versioning models, and deploying them.
A. This is a common error you will face in the project. Just run `zenml logout –local` then `zenml clean`, and then `zenml login –local`, again run the pipeline. It will be resolved.
ADVERTISEMENT:
andalannya, tuk membawa come back hasil. any way gimana
tekniknya? jumpain slot gacor, benar jatuh Tenang Bro and Sis bahas ini. tenang saja mesin di sini yang Permainan terpopuler waktu. ini, hanya satu ini bisa berada hanya di yang menyediakan return on Investment terbesar Daftarkanlah dengan, cemana sih caranya jumpain slot demo yang benar? Santai Bro, kita bahas tenang saja di tempat ini
Gaming tergaco waktu sekarang hanya satu berada Indonesia yaitu pasti menyediakan ROI terbesar
Daftarkanlah hanya di :
Informasi mengenai KING SLOT, Segera Daftar Bersama king selot terbaik dan terpercaya no satu di Indonesia. Boleh mendaftar melalui sini king slot serta memberikan hasil kembali yang paling tinggi saat sekarang ini hanyalah KING SLOT atau Raja slot paling gacor, gilak dan gaco saat sekarang di Indonesia melalui program return tinggi di kingselot serta pg king slot
slot demo gacor
slot demo gacor permainan paling top dan garansi imbal balik hasil besar bersama kdwapp.com
akun demo slot gacor
akun demo slot gacor permainan paling top dan garansi imbal balik hasil besar bersama kdwapp.com
akun slot demo gacor
akun slot demo gacor permainan paling top dan garansi imbal balik hasil besar bersama kdwapp.com
akun demo slot pragmatic
akun demo slot pragmatic permainan paling top dan garansi imbal balik hasil besar bersama kdwapp.com
akun slot demo pragmatic
akun slot demo pragmatic permainan paling top dan garansi imbal balik hasil besar bersama kdwapp.com
akun slot demo
akun slot demo permainan paling top dan garansi imbal balik hasil besar bersama kdwapp.com
akun demo slot
akun demo slot permainan paling top dan garansi imbal balik hasil besar bersama kdwapp.com
slot demo gacor
slot demo gacor permainan paling top dan garansi imbal balik hasil besar bersama jebswagstore.com
akun demo slot gacor
akun demo slot gacor permainan paling top dan garansi imbal balik hasil besar bersama jebswagstore.com
akun slot demo gacor
akun slot demo gacor permainan paling top dan garansi imbal balik hasil besar bersama jebswagstore.com
akun demo slot pragmatic
akun demo slot pragmatic permainan paling top dan garansi imbal balik hasil besar bersama jebswagstore.com
akun slot demo pragmatic
akun slot demo pragmatic permainan paling top dan garansi imbal balik hasil besar bersama jebswagstore.com
akun slot demo
akun slot demo permainan paling top dan garansi imbal balik hasil besar bersama jebswagstore.com
akun demo slot
akun demo slot permainan paling top dan garansi imbal balik hasil besar bersama jebswagstore.com
slot demo gacor
slot demo gacor permainan paling top dan garansi imbal balik hasil besar bersama demoslotgacor.pro
akun demo slot gacor
akun demo slot gacor permainan paling top dan garansi imbal balik hasil besar bersama demoslotgacor.pro
akun slot demo gacor
akun slot demo gacor permainan paling top dan garansi imbal balik hasil besar bersama demoslotgacor.pro
akun demo slot pragmatic
akun demo slot pragmatic permainan paling top dan garansi imbal balik hasil besar bersama demoslotgacor.pro
akun slot demo pragmatic
akun slot demo pragmatic permainan paling top dan garansi imbal balik hasil besar bersama demoslotgacor.pro
akun slot demo
akun slot demo permainan paling top dan garansi imbal balik hasil besar bersama demoslotgacor.pro
akun demo slot
akun demo slot permainan paling top dan garansi imbal balik hasil besar bersama demoslotgacor.pro
slot demo gacor
slot demo gacor permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
akun demo slot gacor
akun demo slot gacor permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
akun slot demo gacor
akun slot demo gacor permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
akun demo slot pragmatic
akun demo slot pragmatic permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
akun slot demo pragmatic
akun slot demo pragmatic permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
akun slot demo
akun slot demo permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
akun demo slot
akun demo slot permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
situs slot terbaru
situs slot terbaru permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
slot terbaru
slot terbaru permainan paling top dan garansi imbal balik hasil besar bersama situsslotterbaru.net
jablay88 permainan paling top dan garansi imbal balik hasil besar bersama jablay88.biz
jadijp88 permainan paling top dan garansi imbal balik hasil besar bersama jadijp88.com
jazz88 permainan paling top dan garansi imbal balik hasil besar bersama jazz88.biz
jurutogel88 permainan paling top dan garansi imbal balik hasil besar bersama jurutogel88.net
kangbet88 permainan paling top dan garansi imbal balik hasil besar bersama kangbet88.biz
kilau88 permainan paling top dan garansi imbal balik hasil besar bersama kilau88.asia
kuningtoto88 permainan paling top dan garansi imbal balik hasil besar bersama kuningtoto88.net
lomboktoto88 permainan paling top dan garansi imbal balik hasil besar bersama lomboktoto88.org
mager88 permainan paling top dan garansi imbal balik hasil besar bersama mager88.biz
mantul888 permainan paling top dan garansi imbal balik hasil besar bersama mantul888.biz
mawartoto88 permainan paling top dan garansi imbal balik hasil besar bersama mawartoto88.asia
meriah88 permainan paling top dan garansi imbal balik hasil besar bersama meriah88.biz
moba88 permainan paling top dan garansi imbal balik hasil besar bersama moba88.org
paristogel88 permainan paling top dan garansi imbal balik hasil besar bersama paristogel88.biz
parsel88 permainan paling top dan garansi imbal balik hasil besar bersama parsel88.net
paus13 permainan paling top dan garansi imbal balik hasil besar bersama paus13.com
pay7777 permainan paling top dan garansi imbal balik hasil besar bersama pay7777.net
planetliga88 permainan paling top dan garansi imbal balik hasil besar bersama planetliga88.net
ratuslot88 permainan paling top dan garansi imbal balik hasil besar bersama ratuslot88.biz
rtp100 permainan paling top dan garansi imbal balik hasil besar bersama rtp100.net
ruby88 permainan paling top dan garansi imbal balik hasil besar bersama ruby88.org
rungkad88 permainan paling top dan garansi imbal balik hasil besar bersama rungkad88.biz
senopati88 permainan paling top dan garansi imbal balik hasil besar bersama senopati88.biz
sis88 permainan paling top dan garansi imbal balik hasil besar bersama sis88.biz
sistoto permainan paling top dan garansi imbal balik hasil besar bersama sistoto.net
sontogel88 permainan paling top dan garansi imbal balik hasil besar bersama sontogel88.com
spin98 permainan paling top dan garansi imbal balik hasil besar bersama spin98.biz
totosaja88 permainan paling top dan garansi imbal balik hasil besar bersama totosaja88.com
warung22 permainan paling top dan garansi imbal balik hasil besar bersama warung22.com
warung88 permainan paling top dan garansi imbal balik hasil besar bersama warung88.asia
winrate999 permainan paling top dan garansi imbal balik hasil besar bersama winrate999.biz
wuzz888 permainan paling top dan garansi imbal balik hasil besar bersama wuzz888.com
999jitu permainan paling top dan garansi imbal balik hasil besar bersama 999jitu.org
adu88 permainan paling top dan garansi imbal balik hasil besar bersama adu88.asia
basket88 permainan paling top dan garansi imbal balik hasil besar bersama basket88.net
batu88 permainan paling top dan garansi imbal balik hasil besar bersama batu88.biz
berita88 permainan paling top dan garansi imbal balik hasil besar bersama berita88.biz
bukalapak88 permainan paling top dan garansi imbal balik hasil besar bersama bukalapak88.net
cipit888 permainan paling top dan garansi imbal balik hasil besar bersama cipit888.asia
delta888 permainan paling top dan garansi imbal balik hasil besar bersama delta888.biz
dosen88 permainan paling top dan garansi imbal balik hasil besar bersama dosen88.org
jago17 permainan paling top dan garansi imbal balik hasil besar bersama jago17.com
jalantoto88 permainan paling top dan garansi imbal balik hasil besar bersama jalantoto88.biz
janjigacor88 permainan paling top dan garansi imbal balik hasil besar bersama janjigacor88.org
jitujp88 permainan paling top dan garansi imbal balik hasil besar bersama jitujp88.com
jokiwin88 permainan paling top dan garansi imbal balik hasil besar bersama jokiwin88.net
juragan66 permainan paling top dan garansi imbal balik hasil besar bersama juragan66.biz
kenzototo88 permainan paling top dan garansi imbal balik hasil besar bersama kenzototo88.biz
kkslot77slot permainan paling top dan garansi imbal balik hasil besar bersama kkslot77slot.com
kompas88 permainan paling top dan garansi imbal balik hasil besar bersama kompas88.biz
kopi88 permainan paling top dan garansi imbal balik hasil besar bersama kopi88.biz
kudajitu88 permainan paling top dan garansi imbal balik hasil besar bersama kudajitu88.biz
kursi88 permainan paling top dan garansi imbal balik hasil besar bersama kursi88.biz
liputan88 permainan paling top dan garansi imbal balik hasil besar bersama liputan88.net
livitoto88 permainan paling top dan garansi imbal balik hasil besar bersama livitoto88.net
lotus88 permainan paling top dan garansi imbal balik hasil besar bersama lotus88.asia
m77casino88 permainan paling top dan garansi imbal balik hasil besar bersama m77casino88.com
majujp88 permainan paling top dan garansi imbal balik hasil besar bersama majujp88.org
mamikos permainan paling top dan garansi imbal balik hasil besar bersama mamikos.org
mamikos88 permainan paling top dan garansi imbal balik hasil besar bersama mamikos88.com
masterplay88 permainan paling top dan garansi imbal balik hasil besar bersama masterplay88.asia
masterplay999 permainan paling top dan garansi imbal balik hasil besar bersama masterplay999.net
medantoto88 permainan paling top dan garansi imbal balik hasil besar bersama medantoto88.biz
medusa888 permainan paling top dan garansi imbal balik hasil besar bersama medusa888.com
meja88 permainan paling top dan garansi imbal balik hasil besar bersama meja88.biz
midasplay88 permainan paling top dan garansi imbal balik hasil besar bersama midasplay88.biz
mijit888 permainan paling top dan garansi imbal balik hasil besar bersama mijit888.net
mposun88 permainan paling top dan garansi imbal balik hasil besar bersama mposun88.net
ibisbudget88 permainan paling top dan garansi imbal balik hasil besar bersama ibisbudget88.com
mercure88 permainan paling top dan garansi imbal balik hasil besar bersama mercure88.com
hotel88 permainan paling top dan garansi imbal balik hasil besar bersama hotel88.net
sheraton88 permainan paling top dan garansi imbal balik hasil besar bersama sheraton88.com
ubud88 permainan paling top dan garansi imbal balik hasil besar bersama ubud88.asia
hardrock88 permainan paling top dan garansi imbal balik hasil besar bersama hardrock88.com
kuta88 permainan paling top dan garansi imbal balik hasil besar bersama kuta88.asia
nasigoreng88 permainan paling top dan garansi imbal balik hasil besar bersama nasigoreng88.com
sate88 permainan paling top dan garansi imbal balik hasil besar bersama sate88.com
rendang88 permainan paling top dan garansi imbal balik hasil besar bersama rendang88.asia
gadogado permainan paling top dan garansi imbal balik hasil besar bersama gadogado.org
kfc88 permainan paling top dan garansi imbal balik hasil besar bersama kfc88.net
pizzahut88 permainan paling top dan garansi imbal balik hasil besar bersama pizzahut88.net
starbucks88 permainan paling top dan garansi imbal balik hasil besar bersama starbucks88.live
sederhana permainan paling top dan garansi imbal balik hasil besar bersama sederhana.org
kopikenangan permainan paling top dan garansi imbal balik hasil besar bersama kopikenangan.asia
angkawin permainan paling top dan garansi imbal balik hasil besar bersama angkawin.net
rockygerung88 permainan paling top dan garansi imbal balik hasil besar bersama rockygerung88.com
monopoli88 permainan paling top dan garansi imbal balik hasil besar bersama monopoli88.com
kimjongun permainan paling top dan garansi imbal balik hasil besar bersama kimjongun.asia
catur88 permainan paling top dan garansi imbal balik hasil besar bersama catur88.asia
tato88 permainan paling top dan garansi imbal balik hasil besar bersama tato88.org
speaker88 permainan paling top dan garansi imbal balik hasil besar bersama speaker88.net
rajah permainan paling top dan garansi imbal balik hasil besar bersama rajah.asia
kunci gitar permainan paling top dan garansi imbal balik hasil besar bersama kuncigitar.org
gitar88 permainan paling top dan garansi imbal balik hasil besar bersama gitar88.asia
gambartato permainan paling top dan garansi imbal balik hasil besar bersama gambartato.com
gambar88 permainan paling top dan garansi imbal balik hasil besar bersama gambar88.org
maxwin888slot permainan paling top dan garansi imbal balik hasil besar bersama maxwin888slot.com
rumah permainan paling top dan garansi imbal balik hasil besar bersama rumah.asia
nada888 permainan paling top dan garansi imbal balik hasil besar bersama nada888.info
musik88 permainan paling top dan garansi imbal balik hasil besar bersama musik88.asia
sewarumah permainan paling top dan garansi imbal balik hasil besar bersama sewarumah.biz